


06 September 2008
Goodreads Collapse Folders
This is yet another greasemonkey script for Goodreads, this time to deal with a minor annoyance.
A GR group (basically a forum) can have "folders" of topics (basically different areas/sub-forums). When you look up a group, you will get a list of all folders, with the last 4 discussions for each folder; on a group with dozens of folders (e.g. the SciFi and Fantasy Book Club) it means you might have to scroll quite a bit to get the (small) link to the folder you're interested in.
So this script will make the folders "expandable", and collapse them by default if they are more than a certain amount (by default 2, but you can customize this threshold). Preview:
Labels: books, GeekDiary, goodreads, greasemonkey
posted by GiacomoL @ 6:07 AM
0 comments
links to this post

02 September 2008
Goodreads Exploder
Another little script for fellow GoodReaders: GoodReads Exploder will add a link to "Explode" all the books on the shelf in different tabs. It saves having to CTRL-click on each book or losing the original shelf page while you browse the books.
Since this might be a bit dangerous with lots of books, if the shelf contains more than 10 books, the script will warn you and give you the option to cancel the operation before your browser "melts". You can change the limit to suit your machine.
This script uses several of the most recent Greasemonkey features (GM_openInTab, getValue, setValue...). It was a lot of fun to write, Greasemonkey really is a fabulous toolkit; the FF Extensions framework is, in comparison, very complicate and burdensome (which I guess is the trade-off for all the power they give developers).
Labels: books, GeekDiary, goodreads, greasemonkey, kdiary
posted by GiacomoL @ 11:26 AM
0 comments
links to this post
01 September 2008
Amazon-to-Goodreads Greasemonkey script
This is a little Greasemonkey script that will add a link to Amazon item pages to see the reviews on Goodreads (if the book is available there). The result will look like this:

You can download it from here: Amazon-to-Goodreads Greasemonkey script 2.0. Note that you will need to install Greasemonkey first, if you haven't already.
I also put the script on Userscripts.org as well.
Labels: books, GeekDiary, goodreads, greasemonkey
posted by GiacomoL @ 7:46 AM
1 comments
links to this post
30 August 2008
w00t!
I'm the top UK-based GoodReads librarian in August 2008: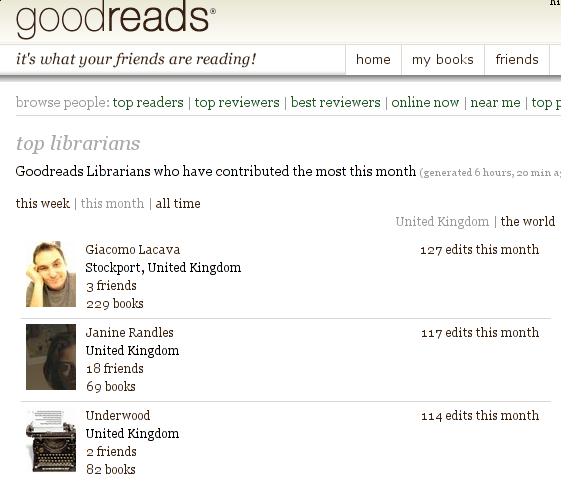
Labels: books, GeekDiary, goodreads, personal
posted by GiacomoL @ 9:58 PM
1 comments
links to this post
26 August 2008
Shelfari bought by Amazon
I just noticed this blog post; so Amazon finally bought one of the new wave of literary social-networking sites I recently listed. I wonder whether they'll now do with Shelfari the sort of thing I suggested for aNobii.
I guess this might be a blow for LibraryThing, GoodReads and aNobii (but it might actually be the kiss of death for Shelfari if it's reduced to an Amazon shopwindow). However, as these things go, we might now see a move from an Amazon competitor to buy or partner with one of the other services.
Me, I don't care: the only service with a serious API is GoodReads, so I'll stick with it :)
Labels: amazon, anobii, GeekDiary, goodreads, shelfari
posted by GiacomoL @ 3:58 PM
0 comments
links to this post
GrEstimator - the web version
I finally bit the bullet and put online an interactive version of my GrEstimator script (which will soon see a new release, by the way).
The GrEstimator Web Service is currently very basic. You provide an email, a GoodReads ID and a shelf (or tag) you want to estimate, and the system will email the result (expressed in a currency of your choice, calculated with exchange rates from WebserviceX's Currency Converter).
The tool is beta ("almost alpha" really), so be gentle and let me know if it dies on you :)
Known issues:
- you have to provide a numerical GoodReads ID, which is the one appearing at the end of the URL when you look up a user (e.g. "http://www.goodreads.com/user/show/1383164"). I've asked to be authorized to look up an ID by providing an email, and I'm waiting for the response; once I'm allowed, you'll be able to just provide the email you use with GR.
- you cannot estimate more than 200 books on a shelf; this is a limitation of the GoodReads API.
- books not listed on Amazon will be ignored.
- it currently spawns a thread for each estimate. I have to implement a system of queues to limit the amount of threads running at any given time, just in (the remote) case the service becomes popular.
- you cannot choose the output currency, it's USD only. This will be fixed soon with a new option. Fixed.
- the result is based on average prices. I'll soon add an option to say if you want that or rather the maximum potential price (which really tends to be funny). Fixed.
- the service does go through all the Amazon locales (.com, .co.uk, .de, .fr, .ca, .jp in this order) but only if item lookup fails on the previous locale. This means that, if I find a book on .com marked as unavailable, I will still consider it as "found" and won't repeat the lookup on a different locale. I actually just realized this as I was writing the post, it will be fixed very soon. Fixed.
- producing a "blog badge".
- pulling prices from somewhere else than Amazon.
- an "update" feature of some sort would be nice.
Labels: books, foreverythingelsetherespython, GeekDiary, goodreads, grest
posted by GiacomoL @ 9:49 AM
0 comments
links to this post
21 August 2008
How much is your bookshelf worth?
Just for fun, I wrote a little python script that will pull a feed of books from GoodReads and calculate their total worth according to Amazon.
Requirements:
- Python 2.5
- an Amazon Web Services Developer Key (get one from the AWS site)
- a GoodReads account
The script allows for shelf-specific filtering and supports different Amazon locales, with output configurable to be in any currency. Due to a limitation in the GoodReads API, it will estimate only the first 200 books.
You can see it in action using the web-based version
Download: GR_Estimator 1.1
- Release 1.1
- Added support for multiple currencies
- fixed a few bugs
- Release 1.0
- Initial release
Labels: amazon, books, foreverythingelsetherespython, GeekDiary, goodreads, grest
posted by GiacomoL @ 6:40 PM
0 comments
links to this post
19 August 2008
A lil' script
Since my itch is now scratched, I might as well make the code available: GenBooks 1.0 is the little script I used to generate my list of books by pulling my "favourites" shelf on GoodReads. It works with python templates and even embeds your Amazon Associate ID. Requires Python 2.5 (because it uses the new ETree module) and the Python Imaging Library 1.1.x. There is no license, it's all public domain. Have fun.
Labels: books, foreverythingelsetherespython, GeekDiary, goodreads
posted by GiacomoL @ 8:13 PM
4 comments
links to this post
My favourite books...
... are now listed here. I generated the list while playing around with the GoodReads API and the Python Imaging Library. I'm trying to think of something else to build with the GR API... any suggestions?
Labels: books, foreverythingelsetherespython, GeekDiary, goodreads, personal
posted by GiacomoL @ 4:26 PM
0 comments
links to this post
16 August 2008
Tag your f***ing books!
After a few days wandering around "literary" social-networking sites, I'm feeling a bit frustrated by how people interpret their participation in a very solipsistic way. Listing your own books is half the fun, I get it, but certainly the other half is hooking up with other like-minded bookworm geeks; you should put in a little effort to make your shelf accessible to them. Why then few can be bothered to tag their books? Without tags, I'm left to dig through hundreds of items I don't care about, whereas even a little classification (like separating novels and non-fiction, or fantasy and contemporary) would go a long way to help me define that you like the same sort of harrypotterish works I (might or might not) enjoy.
So please, if you are serious about this sort of sites, try to tag your books, even a little bit. Splitting your shelf in groups containing less than 100 items would already be enough, especially if your collection contains 200+ editions of books blatantly plagiarizing JRR Tolkien.
Labels: anobii, books, GeekDiary, goodreads, librarything, personal, shelfari
posted by GiacomoL @ 5:54 PM
0 comments
links to this post
14 August 2008
Export your books from aNobii to GoodReads
This is a quick & dirty hack to translate your book data from the CSV file produced by aNobii to the format accepted by GoodReads (and LibraryThing, apparently). The main advantages of this approach are that you will maintain your reviews and rating, and if GoodReads fails to find a book it will tell you the title (whereas if you just use a list of ISBNs, it won't).
Cons: I couldn't be bothered to mess with strptime, so you might lose your reading date; also, all your books will be imported with the default status ("read" for me).
You can download the script from here, it works with Python 2.4 and 2.5 (probably 2.3 as well). Feel free to improve it, I scratched my itch so I'm happy as it is.
Labels: anobii, foreverythingelsetherespython, GeekDiary, goodreads, librarything
posted by GiacomoL @ 8:00 AM
3 comments
links to this post
10 August 2008
aNobii vs GoodReads
I've recently signed up to two book-listing, social-networking, web-2.0 sites, aNobii and GoodReads. The fundamental idea is shared by the two: you list and rate your books, then hook up with friends and fellow readers. Thoughts:
- GoodReads is quite English-oriented; despite being able to distinguish between languages, the amount of non-English books is quite small. aNobii's catalogue is much better, possibly because it's the biggest player and so it attracts a larger crowd. This is more or less why I switched from GR to aN: several books that I had to manually add to GR were already in aN, and my friends were also there already. As it turns out, this is just due to the specific audience: aNobii's population is overwhelmingly Italian, so Italian books are easier to find there because they have already been added.
- Adding a book to your list is fairly easy in both systems, but aN has several different interfaces so it feels somehow more adaptable to your own style. However, if the book is not listed or you want to edit details for an existing book, it's a pain in the neck to do it in aN, whereas it's much more easy to do in GR.
- Annoyingly, if you mass-import lists of books, both sites aNobii won't tell you which ones failed to be added, so finding them becomes a game of patience. I know there are at least 5 books which are now in my GR account but aN failed to identify. aN also has a webpage-scraping feature that fails miserably on GR's pages. GR will report the failed books, as long as you supply the books' titles in the uploaded file -- if you only send ISBNs, it will not tell you which ones failed.
- Consistency in metadata is clearly a challenge for both. aN annoyingly differentiates between title and "subtitle", so "serial" books end up all over the place. For example, "Batman: The Killing Joke" (which is a self-contained graphic novel) could (and does) end up as "Batman"/"The Killing Joke", "The Killing Joke"/"Batman vol.XYZ", or "Batman: The Killing Joke"/"vol. XYZ" (and obviously "Vol.X", "vol. X", "Volume X"...). Since in several UI screens only the title is displayed, it can become difficult to differentiate (I have several "Batman" listed, but which is "The Killing Joke" and which is "The Dark Knight Returns"?). GR doesn't feature this split, so it's easier for users to self-enforce consistency, somehow. This said, GR encourages you to add random details in parentheses appended to the end of the title, for example the particular imprint (e.g. "Il Fu Mattia Pascal (Classici Moderni)"), or version, or what you feel like mentioning, so it also adds an unnecessary random element.
- GR's metadata includes binding, but it's an arbitrary and case-sensitive field, so you can have "hardcover", "Hardcover" and "Hard Cover" as three different modes. It would be much more useful to have a pre-populated listbox with the most common values, plus an "Other" option that will allow you to enter an arbitrary value.
- GR's rating is 6-levels deep (from 0 stars to 5), aN's is only 4-levels (from 1 to 4 stars).
- They both allow you to tag books with arbitrary words. In GR, tagging (or "shelving") is everything: it's what you do to distinguish "read" from "unread", for example; there is no mass-tagging feature yet, which is annoying, but it's faster to tag a single book from the master ("your shelf") view than it is in aN. Vice-versa, aN is much better when you want to tag several books at once, but a bit laborious if you want to tag a book from the master view (you have to go in "book view" first). Also, you can see aN was not built on tags like GR, it's clearly a feature which was added later in the application life.
- aN has loads of features to define how you got hold of the book (even listing shops and libraries), and has an in-built lending/trading exchange, whereas GR only has a generic checkbox to mark the book as "I'd be willing to send/swap".
- Both allow you to review books. Somehow it feels a more central concept in GR, whereas in aN you are pushed to define when/how you read the book rather than reviewing it.
- The "social" features are a bit different. In both you have groups and friends, but aN also has (presumably American) "Neighbors", which is an euphemism for "stalked": people you don't know but you want to track anyway. The social aspect seems really more "inbuilt" in aN, which will show your "compatibility level" with friends and try to match you with people with similar shelves.
- GR gives more relevance to authors, who can have their own page (and presumably some extra features). Just to name one, Neil Gaiman uses GoodReads.
- Both have some sort of facility for bloggers. aNobii lets you use your Amazon associate ID, which is nice; however it's up to you to do all the CSS magic to integrate the widget with the look&feel of the blog.
- aNobii is broken in Konqueror. GoodReads doesn't officially support Konqueror, but it works nonetheless (probably because they tested it in Safari, which is very similar).
- aNobii's API is ridiculously useless, it doesn't even return ISBNs. GoodReads' API is much better, easier to work with and more complete.
- All in all, GR seems to be more about listing and tagging your books, whereas aN is more about matching you with people with similar books/tastes/favourite bookshop.
Labels: anobii, GeekDiary, goodreads, personal











